YARN (Yet Another Resource Negotiator) is the resource management layer for the Apache Hadoop ecosystem. YARN has been available for several releases. YARN is a resource scheduler designed to work on existing and new Hadoop clusters. The seemingly trivial split of resource scheduling from the MapReduce data flow opens up a whole new range of possibilities for Hadoop and Big Data processing. A separate scheduler allows for better utilization and scalability of the cluster, while simultaneously providing a platform for other non-MapReduce applications to take advantage of the Hadoop Distributed File System and run-time environment.
From a larger vantage point, YARN can be viewed as a cluster-wide Operating System that provides the essential services for applications to take advantage of a large dynamic and parallel resource infrastructure. Applications written in any language can now take advantage of the combined Hadoop compute and storage assets within any size cluster. YARN is capable of running on a single cluster node or desktop machine.
A basic Apache Hadoop version 2 system has two core components
- The Hadoop Distributed File System (HDFS) for storing data
- Hadoop YARN for implementing applications to process data
Other Apache Hadoop components, such as Pig and Hive, can be added after the two core components are installed and operating properly. In a YARN cluster, there are two types of hosts:
- The ResourceManager is the master daemon that communicates with the client, tracks resources on the cluster, and orchestrates work by assigning tasks to NodeManagers.
- A NodeManager is a worker daemon that launches and tracks processes spawned on worker hosts.
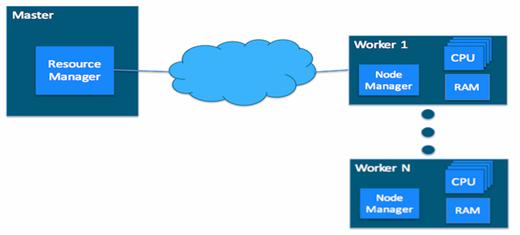
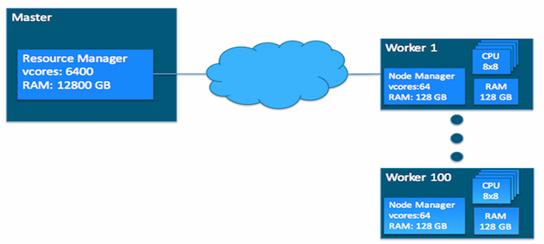
The YARN configuration file is an XML file that contains properties. This file is placed in a well-known location on each host in the cluster and is used to configure the ResourceManager and NodeManager. By default, this file is named yarn-site.xml. The basic properties in this file used to configure YARN are covered in the later sections. YARN currently defines two resources, vcores and memory. Each NodeManager tracks its own local resources and communicates its resource configuration to the ResourceManager, which keeps a running total of the cluster’s available resources. By keeping track of the total, the ResourceManager knows how to allocate resources as they are requested. (Vcore has a special meaning in YARN. You can think of it simply as a “usage share of a CPU core.” If you expect your tasks to be less CPU-intensive (sometimes called I/O-intensive), you can set the ratio of vcores to physical cores higher than 1 to maximize your use of hardware resources.)
Containers are an important YARN concept. You can think of a container as a request to hold resources on the YARN cluster. Currently, a container hold request consists of vcore and memory.
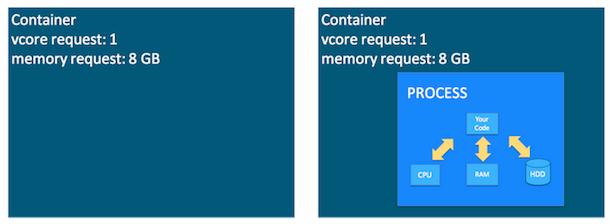
Once a hold has been granted on a host, the NodeManager launches a process called a task. The right side of figure shows the task running as a process inside a container.
An application is a YARN client program that is made up of one or more tasks. For each running application, a special piece of code called an ApplicationMaster helps coordinate tasks on the YARN cluster. The ApplicationMaster is the first process run after the application starts.
An application running tasks on a YARN cluster consists of the following steps:
- The application starts and talks to the ResourceManager for the cluster:
- The ResourceManager makes a single container request on behalf of the application:
- The ApplicationMaster starts running within that container:
- The ApplicationMaster requests subsequent containers from the ResourceManager that are allocated to run tasks for the application. Those tasks do most of the status communication with the ApplicationMaster allocated in Step 3):
- Once all tasks are finished, the ApplicationMaster exits. The last container is de-allocated from the cluster.
- The application client exits. (The ApplicationMaster launched in a container is more specifically called a managed AM. Unmanaged ApplicationMasters run outside of YARN’s control. Llama is an example of an unmanaged AM.)
The central ResourceManager runs as a standalone daemon on a dedicated machine and acts as the central authority for allocating resources to the various competing applications in the cluster. The ResourceManager has a central and global view of all cluster resources and, therefore, can provide fairness, capacity, and locality across all users. Depending on the application demand, scheduling priorities, and resource availability, the ResourceManager dynamically allocates resource containers to applications to run on particular nodes. A container is a logical bundle of resources (e.g., memory, cores) bound to a particular cluster node. To enforce and track such assignments, the ResourceManager interacts with a special system daemon running on each node called the NodeManager. Communications between the ResourceManager and NodeManagers are heartbeat based for scalability. NodeManagers are responsible for local monitoring of resource availability, fault reporting, and container life-cycle management (e.g., starting and killing jobs). The ResourceManager depends on the NodeManagers for its “global view” of the cluster.
User applications are submitted to the ResourceManager via a public protocol and go through an admission control phase during which security credentials are validated and various operational and administrative checks are performed. Those applications that are accepted pass to the scheduler and are allowed to run. Once the scheduler has enough resources to satisfy the request, the application is moved from an accepted state to a running state. Aside from internal bookkeeping, this process involves allocating a container for the ApplicationMaster and spawning it on a node in the cluster. Often called “container 0,” the ApplicationMaster does not get any additional resources at this point and must request and release additional containers.
The ApplicationMaster is the “master” user job that manages all life-cycle aspects, including dynamically increasing and decreasing resources consumption (i.e., containers), managing the f low of execution (e.g., in case of MapReduce jobs, running reducers against the output of maps), handling faults and computation skew, and performing other local optimizations. The ApplicationMaster is designed to run arbitrary user code that can be written in any programming language, as all communication with the ResourceManager and NodeManager is encoded using extensible network protocols (i.e., Google Protocol Buffers, http://code.google.com/p/protobuf/).
YARN makes few assumptions about the ApplicationMaster, although in practice it expects most jobs will use a higher-level programming framework. By delegating all these functions to ApplicationMasters, YARN’s architecture gains a great deal of scalability, programming model f lexibility, and improved user agility. For example, upgrading and testing a new MapReduce framework can be done independently of other running MapReduce frameworks.
Typically, an ApplicationMaster will need to harness the processing power of multiple servers to complete a job. To achieve this, the ApplicationMaster issues resource requests to the ResourceManager. The form of these requests includes specification of locality preferences (e.g., to accommodate HDFS use) and properties of the containers. The ResourceManager will attempt to satisfy the resource requests coming from each application according to availability and scheduling policies. When a resource is scheduled on behalf of an ApplicationMaster, the ResourceManager generates a lease for the resource, which is acquired by a subsequent ApplicationMaster heartbeat. A token-based security mechanism guarantees its authenticity when the ApplicationMaster presents the container lease to the NodeManager. In MapReduce, the code running in the container can be a map or a reduce task. Commonly, running containers will communicate with the ApplicationMaster through an application-specific protocol to report status and health information and to receive framework-specific commands. In this way, YARN provides a basic infrastructure for monitoring and life-cycle management of containers, while application-specific semantics are managed independently by each framework. This design is in sharp contrast to the original Hadoop version 1 design, in which scheduling was designed and integrated around managing only MapReduce tasks.
YARN Scheduling
YARN has a pluggable scheduling component. Depending on the use case and user needs, administrators may select either a simple FIFO (first in, first out), capacity, or fair share scheduler. The scheduler class is set in yarn-default.xml. Information about the currently running scheduler can be found by opening the ResourceManager web UI and selecting the Scheduler option under the Cluster menu on the left (e.g., http://cluster:8088/cluster/scheduler). The various scheduler are
- FIFO Scheduler – The original scheduling algorithm that was integrated within the Hadoop version 1. JobTracker was called the FIFO scheduler, meaning “first in, first out.” The FIFO scheduler is basically a simple “first come, first served” scheduler in which the JobTracker pulls jobs from a work queue, oldest job first. Typically, FIFO schedules have no sense of job priority or scope. The FIFO schedule is practical for small workloads, but is feature-poor and can cause issues when large shared clusters are used.
- Capacity Scheduler – The Capacity scheduler is another pluggable scheduler for YARN that allows for multiple groups to securely share a large Hadoop cluster. Developed by the original Hadoop team at Yahoo!, the Capacity scheduler has successfully been running many of the largest Hadoop clusters. To use the Capacity scheduler, an administrator configures one or more queues with a predetermined fraction of the total slot (or processor) capacity. This assignment guarantees a minimum amount of resources for each queue. Administrators can configure soft limits and optional hard limits on the capacity allocated to each queue. Each queue has strict ACLs (Access Control Lists) that control which users can submit applications to individual queues. Also, safeguards are in place to ensure that users cannot view or modify applications from other users.
- Fair Scheduler – Fair scheduling is a method of assigning resources to applications such that all applications get, on average, an equal share of resources over time. In the Fair scheduler model, every application belongs to a queue. YARN containers are given to the queue with the least amount of allocated resources. Within the queue, the application that has the fewest resources is assigned the container. By default, all users share a single queue, called “default.” If an application specifically lists a queue in a container resource request, the request is submitted to that queue. It is also possible to configure the Fair scheduler to assign queues based on the user name included with the request. The Fair scheduler supports a number of features such as weights on queues (heavier queues get more containers), minimum shares, maximum shares, and FIFO policy within queues, but the basic idea is to share the resources as uniformly as possible.
