Pig is a high-level platform for creating MapReduce programs used with Hadoop. The language for this platform is called Pig Latin. Pig Latin abstracts the programming from the Java MapReduce idiom into a notation which makes MapReduce programming high level, similar to that of SQL for RDBMS systems. Pig Latin can be extended using UDF (User Defined Functions) which the user can write in Java, Python, JavaScript, Ruby or Groovy and then call directly from the language. It is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets.
Pig was originally developed at Yahoo Research around 2006 for researchers to have an ad-hoc way of creating and executing map-reduce jobs on very large data sets. In 2007, it was moved into the Apache Software Foundation.
In comparison to SQL, Pig
- uses lazy evaluation,
- uses extract, transform, load (ETL),
- is able to store data at any point during a pipeline,
- declares execution plans,
- supports pipeline splits, thus allowing workflows to proceed along DAGs instead of strictly sequential pipelines.
On the other hand, it has been argued DBMSs are substantially faster than the MapReduce system once the data is loaded, but that loading the data takes considerably longer in the database systems. It has also been argued RDBMSs offer out of the box support for column-storage, working with compressed data, indexes for efficient random data access, and transaction-level fault tolerance.
Pig Latin is procedural and fits very naturally in the pipeline paradigm while SQL is instead declarative. In SQL users can specify that data from two tables must be joined, but not what join implementation to use (You can specify the implementation of JOIN in SQL, thus “… for many SQL applications the query writer may not have enough knowledge of the data or enough expertise to specify an appropriate join algorithm.”). Pig Latin allows users to specify an implementation or aspects of an implementation to be used in executing a script in several ways. In effect, Pig Latin programming is similar to specifying a query execution plan, making it easier for programmers to explicitly control the flow of their data processing task
At the present time, Pig’s infrastructure layer consists of a compiler that produces sequences of Map-Reduce programs, for which large-scale parallel implementations already exist (e.g., the Hadoop subproject). Pig’s language layer currently consists of a textual language called Pig Latin, which has the following key properties:
- Ease of programming. It is trivial to achieve parallel execution of simple, “embarrassingly parallel” data analysis tasks. Complex tasks comprised of multiple interrelated data transformations are explicitly encoded as data flow sequences, making them easy to write, understand, and maintain.
- Optimization opportunities. The way in which tasks are encoded permits the system to optimize their execution automatically, allowing the user to focus on semantics rather than efficiency.
- Users can create their own functions to do special-purpose processing.
Pig is made up of two (count ‘em, two) components:
- The language itself: As proof that programmers have a sense of humor, the programming language for Pig is known as Pig Latin, a high-level language that allows you to write data processing and analysis programs.
- The Pig Latin compiler: The Pig Latin compiler converts the Pig Latin code into executable code. The executable code is either in the form of MapReduce jobs or it can spawn a process where a virtual Hadoop instance is created to run the Pig code on a single node.
The sequence of MapReduce programs enables Pig programs to do data processing and analysis in parallel, leveraging Hadoop MapReduce and HDFS. Running the Pig job in the virtual Hadoop instance is a useful strategy for testing your Pig scripts. The figure shows how Pig relates to the Hadoop ecosystem.
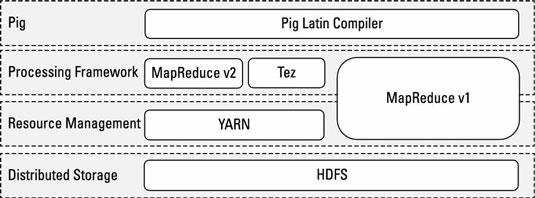
Pig programs can run on MapReduce v1 or MapReduce v2 without any code changes, regardless of what mode your cluster is running. However, Pig scripts can also run using the Tez API instead. Apache Tez provides a more efficient execution framework than MapReduce. YARN enables application frameworks other than MapReduce (like Tez) to run on Hadoop. Hive can also run against the Tez framework.
Pig Philosophy
The Pig team produced a statement of the project’s philosophy that summarizes what Pig aspires to be
- Pigs eat anything – Pig can operate on data whether it has metadata or not. It can operate on data that is relational, nested, or unstructured. And it can easily be extended to operate on data beyond files, including key/value stores, databases, etc.
- Pigs live anywhere – Pig is intended to be a language for parallel data processing. It is not tied to one particular parallel framework. It has been implemented first on Hadoop, but we do not intend that to be only on Hadoop.
- Pigs are domestic animals – Pig is designed to be easily controlled and modified by its users. Pig allows integration of user code wherever possible, so it currently supports user-defined field transformation functions, user defined aggregates, and user defined conditionals. These functions can be written in Java or in scripting languages that can compile down to Java (e.g., Jython). Pig supports user provided load and store functions. It supports external executables via its stream command and MapReduce JARs via its mapreduce command. It allows users to provide a custom partitioner for their jobs in some circumstances, and to set the level of reduce parallelism for their jobs.
Pig is MapReduce simplified. It is a combination of the Pig compiler and the Pig Latin script, which is a programming language designed to ease the development of distributed applications for analyzing large volumes of data. We refer to the whole entity as Pig.
The high-level language code written in the Pig Latin script gets compiled into sequences of the MapReduce Java code and it is amenable to parallelization. Pig Latin promotes the data to become the main concept behind any program written in it. It is based on the dataflow paradigm, which works on a stream of data to be processed; this data is passed through instructions, which processes the data. This programming style is analogous to how electrical signals flow through circuits or water flows through pipes.
This dataflow paradigm is in stark contrast to the control flow language, which works on a stream of instructions, and operates on external data. In a traditional program, the conditional executions, jumps, and procedure calls change the instruction stream to be executed.
Processing statements in Pig Latin consist of operators, which take inputs and emit outputs. The inputs and outputs are structured data expressed in bags, maps, tuples, and scalar data. Pig resembles a dataflow graph, where the directed vertices are the paths of data and the nodes are operators (such as FILTER, GROUP, and JOIN) that process the data. In Pig Latin, each statement executes as soon as all data reaches them in contrast to a traditional program that executes as soon as it encounters the statement.
A programmer writes code using a set of standard data-processing Pig operators, such as JOIN, FILTER, GROUP BY, ORDER BY, and UNION. These are then translated into MapReduce jobs. Pig itself does not have the capability to run these jobs and it delegates this work to Hadoop. Hadoop acts as an execution engine for these MapReduce jobs.
It is imperative to understand that Pig is not a general purpose programming language with all the bells and whistles that come with it. For example, it does not have the concept of control flow or scope resolution, and has minimal variable support, which many developers are accustomed to in traditional languages. This limitation can be overcome by using User Defined Functions ( UDFs), which is an extensibility feature of Pig.
Pig Latin is designed as a dataflow language to address the following limitations of MapReduce
- Complex workarounds have to be implemented in MapReduce even for the simplest of operations like projection, filtering, and joins.
- The MapReduce code is difficult to develop, maintain, and reuse, sometimes taking the order of the magnitude than the corresponding code written in Pig.
- It is difficult to perform optimizations in MapReduce because of its implementation complexity.
Pig is typically used in situations where the solution can be expressed as a Directed Acyclic Graph (DAG), involving the combination of standard relational operations of Pig (join, aggregation, and so on) and utilizing custom processing code via UDFs written in Java or a scripting language. This implies that if you have a very complex chain of tasks where the outputs of each job feeds as an input to the next job, Pig makes this process of chaining the jobs easy to accomplish.
Pig is useful in Big Data workloads where there is one very large dataset, and processing on that dataset includes constantly adding in new small pieces of data that will change the state of the large dataset. Pig excels in combining the newly arrived data so that the whole of the data is not processed, but only the delta of the data along with the results of the large data is processed efficiently. Pig provides operators that perform this incremental processing of data in a reasonable amount of time.
The physical plan that Pig prepares is a series of MapReduce jobs, which in local mode Pig runs in the local JVM and in MapReduce mode Pig runs on a Hadoop cluster.
