An ‘Incident’ is any event which is not part of the standard operation of the service and which causes, or may cause, an interruption or a reduction of the quality of the service.
The objective of Incident Management is to restore normal operations as quickly as possible with the least possible impact on either the business or the user, at a cost-effective price.
Inputs for Incident Management mostly come from users, but can have other sources as well like management Information or Detection Systems. The outputs of the process are RFC’s (Requests for Changes), resolved and closed Incidents, management information and communication to the customer.
Incident management (IcM) is a term describing the activities of an organization to identify, analyze, and correct hazards to prevent a future re-occurrence. These incidents within a structured organization are normally dealt with by either an Incident Response Team (IRT), or an Incident Management Team (IMT). These are often designated before hand, or during the event and are placed in control of the organization whilst the incident is dealt with, to restore normal functions.
There are three basic types of events:
- Normal—a normal event does not affect critical components or require change controls prior to the implementation of a resolution. Normal events do not require the participation of senior personnel or management notification of the event.
- Escalation – an escalated event affects critical production systems or requires that implementation of a resolution that must follow a change control process. Escalated events require the participation of senior personnel and stakeholder notification of the event.
- Emergency – an emergency is an event which may
- impact the health or safety of human beings
- breach primary controls of critical systems
- materially affect component performance or because of impact to component systems prevent activities which protect or may affect the health or safety of individuals
- be deemed an emergency as a matter of policy or by declaration by the available incident coordinator
Terminologies
- Incident – An Incident is defined as an unplanned interruption or reduction in quality of an IT service (a Service Interruption).
- Incident Escalation Rules – A set of rules defining a hierarchy for escalating Incidents, and triggers which lead to escalations. Triggers are usually based on Incident severity and resolution times.
- Incident Management Report – A report supplying Incident-related information to the other Service Management processes.
- Incident Model – An Incident Model contains the pre-defined steps that should be taken for dealing with a particular type of Incident. This is a way to ensure that routinely occurring Incidents are handled efficiently and effectively.
- Incident Prioritization Guideline – The Incident Prioritization Guideline describes the rules for assigning priorities to Incidents, including the definition of what constitutes a Major Incident. Since Incident Management escalation rules are usually based on priorities, assigning the correct priority to an Incident is essential for triggering appropriate escalations.
- Incident Record – A set of data with all details of an Incident, documenting the history of the Incident from registration to closure. An Incident is defined as an unplanned interruption or reduction in quality of an IT service. Every event that could potentially impair an IT service in the future is also an Incident (e.g. the failure of one hard-drive of a set of mirrored drives).
- Incident Status Information – A message containing the present status of an Incident sent to a user who earlier reported a service interruption. Status information is typically provided to users at various points during an Incident’s lifecycle.
- Major Incident – Major Incidents cause serious interruptions of business activities and must be solved with greater urgency.
- Major Incident Review – A Major Incident Review takes place after a Major Incident has occurred. The review documents the Incident’s underlying causes (if known) and the complete resolution history, and identifies opportunities for improving the handling of future Major Incidents.
- Notification of Service Failure – The reporting of a service failure to the Service Desk, for example by a user via telephone or e-mail, or by a system monitoring tool.
- Pro-Active User Information – A notification to users of existing or imminent service failures even if the users are not yet aware of the interruptions, so that users are in a position to prepare themselves for a period of service unavailability.
- Status Inquiry – An inquiry regarding the present status of an Incident or Service Request, usually from a user who earlier reported an Incident or submitted a request.
- Support Request – A request to support the resolution of an Incident or Problem, usually issued from the Incident or Problem Management processes when further assistance is needed from technical experts.
- User Escalation – Escalation regarding the processing of an Incident or Service Request, initiated by a user experiencing delays or a failure to restore their services.
The goal of incident management is to restore normal service operation as quickly as possible following an incident, while minimizing impact to business operations and ensuring quality is maintained.
End users log incidents by
- Employee Self Service
- Inbound Email Actions
Types of Incidents
Incidents are classified as
- Repudiation – Repudiation is when a person or program, acting on behalf of another person, performs an invalid action.
- Reconnaissance Attack – Collecting or discovering information about any individual or organization that might be useful in attacking that individual or organization is known as reconnaissance. DSL and cable modem connections are more exposed than others to reconnaissance attacks because the connections are usually open, which allows more time for attackers to attack the systems. Port scanning, or running a program that remotely finds which ports are open or closed on remote systems, is one of the most common types of reconnaissance attacks.
- Harassment – Harassing an individual using the Internet is a cyber crime in which the attacker sends a harassing message to a victim using e-mail, instant message, or any other form of online communication. Extreme cases of harassment include cyber stalking, in which electronic means are used to follow or intimidate the victim.
- Extortion – An extortionist forces the victim to pay money to the attacker by threatening to reveal information that could lead to a severe loss for the victim. This loss could be data/information-related, or it could be a simple financial threat.
- Pornography Trafficking – Using company computers for pornography is usually against company policy, and some forms of pornography are against the law. Computers and networks are being used extensively worldwide to store, send, and receive child pornography. Users embed pornographic images in other images, making it difficult to track the flow. One famous technology used for this purpose is steganography, discussed in a later chapter.
- Organized Crime Activity – Some organized illegal activities, such as drug trafficking, illegal passport and visa creation, running prostitution rackets, and online smuggling, are done with the help of computers.
- Subversion – Subversion is an incident in which a system does not behave in the expected manner. This leads the users to believe that this behavior is due to an attack on the integrity of the system, network, or application. In reality, it is something else entirely. An example of this would be placing a bogus financial server to discover credit card numbers or illegally index Web pages. In a subversive incident the perpetrator modifies the Web links so that whenever anyone uses one of the links, they are redirected to an unrelated Web address.
- Hoax – A hoax is an e-mail warning of a virus that may have devastating effects on the system. The virus does not really exist, but a specific company is blamed for its imaginary effects, causing panic and unnecessary blame. The hoax convinces people to send e-mails to others, informing them about this supposed virus, panicking users who can then cause damage to their systems.
- Caveat – A caveat is another type of warning, like a “Beware” sign posted near a dangerous area. It may be in the form of a legal notice that could lead to a court hearing. It may also just be a simple principle, as in caveat emptor. This means “buyer beware,” as it is the buyer’s job to check out the item before he or she pays for it.
Security Incidents
A security incident can be
- Evidence of data tampering
- Unauthorized access or attempts at unauthorized access from internal and external sources
- Threats and attacks by an electronic medium
- Defaced Web pages
- Detection of some unusual activity, such as possibly malicious code or modified traffic patterns
- Denial-of-service attacks
- Other malicious attacks, such as virus attacks, that damage the servers or workstations
- Other types of incidents that weaken the trust and confidence in information technology systems
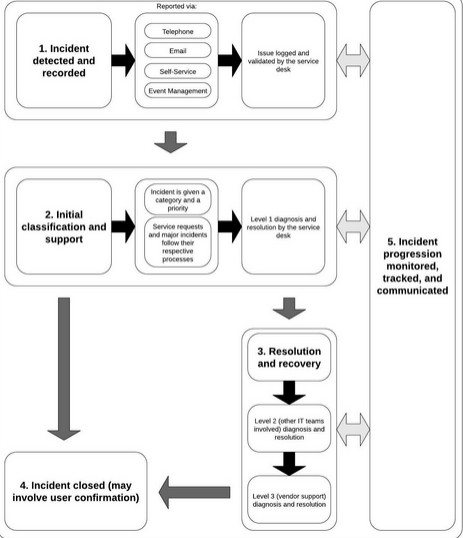
The “Incident Lifecycle”
ITIL recommends that incidents be managed through a lifecycle, or process, that includes a number of steps, activities, or sub-processes – from the initial identification or reporting of the incident through to its resolution and the closure of the incident record. This is the order:
- Incident detection and recording
- Initial classification and support
- Escalation to a major incident process where needed
- Invocation of the service request process if not an incident
- Investigation and diagnosis
- Resolution and recovery
- Incident closure
Continuous ownership, monitoring, tracking, and communication are involved throughout each step as per the diagram below.
The benefits of incident management include, but are not restricted to:
- Shortening the “incident lifecycle” and decreasing downtime, thus maximizing business productivity.
- Resolving incidents before they can adversely impact business operations.
- Making better use of potentially scarce IT resources. Having defined roles and responsibilities and a single, consistent process not only speeds things up but also reduces duplication of effort and wastage.
- Facilitating better collaboration between different IT teams and preventing dropped issues or issues “ping-ponging” between teams.
- The ability to leverage existing knowledge to speed up resolution.
- Reducing the costs associated with both IT service delivery and IT support.
- Reducing the adverse effect of business-impacting incidents. This might potentially include lost revenue, lost reputation, or even lost customers.
- The ability to identify, and act on, opportunities to improve IT services and IT service delivery.
- Improving customer service and the business’s perceptions of the IT organization as a whole.
Categorizing and Prioritization
Categories are used by the incident management system to create automatic assignment rules or notifications like the incident state. This allows the service desk to track how much work has been done and what the next step in the process might be. ITIL uses three metrics for determining the order in which incidents are processed. All three are supported by Incident forms:
- Impact: The effect an incident has on business.
- Urgency: The extent to which the incident’s resolution can bear delay.
- Priority: How quickly the service desk should address the incident.
ITIL suggests that priority be made dependent on impact and urgency. In the base system, this is true on Incident forms. Priority is generated from urgency and impact according to the following data lookup rules
| Impact | Urgency | Priority |
| 1 – High | 1 – High | 1 – Critical |
| 1 – High | 2 – Medium | 2 – High |
| 1 – High | 3 – Low | 3 – Moderate |
| 2 – Medium | 1 – High | 2 – High |
| 2 – Medium | 2 – Medium | 3 – Moderate |
| 2 – Medium | 3 – Low | 4 – Low |
| 3 – Low | 1 – High | 3 – Moderate |
| 3 – Low | 2 – Medium | 4 – Low |
| 3 – Low | 3 – Low | 5 – Planning |
Escalation of Incidents
It is done on basis of
- Service Level Agreements: SLAs monitor the progress of the incident according to defined rules. As time passes, the SLA will dial up the priority of the incident, and leave a marker as to its progress. SLAs can also be used as a performance indicator for the service desk.
- Inactivity Monitors: The inactivity monitors prevent incidents from slipping through the cracks by generating an event, which in turn can create an email notification or trigger a script, when an incident has gone a certain amount of time without being updated.
Investigation and Diagnosis of Incidents
Like the initial diagnosis and investigation, investigation and diagnosis are largely human processes. The service desk can continue to use the information provided within by the Incident form and the CMDB to solve the problem. Work notes can be appended to the incident as it is being evaluated, which facilitates communication between all of the concerned parties. These work notes and other updates can be communicated to the concerned parties through email notifications.
Resolution and Recovery of Incidents
After the incident is considered resolved, the incident state should be set to Resolved by the service desk. The escalators will be stopped and the service desk may review the information within the incident. After a sufficient period of time has passed, assuming that the user who opened the incident is satisfied, the incident state may be set to closed.
If an incident’s cause is understood but cannot be fixed, the service desk can easily generate a problem from the incident, which will be evaluated through the problem management process. If the incident creates the need for a change in IT services, the service desk can easily generate a change from the incident, which will be evaluated through the change management process.
Closure of Incidents
Closed incidents will be filtered out of view, but will remain in the system for reference purposes. Closed incidents can be reopened if the user or service desk believes that it needs to be reopened. Incidents that are on the Related Incidents list of a problem can be configured to close automatically when the problem is closed through business rules.
Incident Team
The security incident coordinator manages the response process and is responsible for assembling the team. The coordinator will ensure the team includes all the individuals necessary to properly assess the incident and make decisions regarding the proper course of action. The incident team meets regularly to review status reports and to authorize specific remedies. The team should utilize a pre-allocated physical and virtual meeting place.
Incident Triage
The name triage comes from a French medical term, which describes a situation in which you have limited resources and have to decide on the priorities of your actions based on the severity of particular cases.
In the incident handling process, the triage phase consists of three sub-phases: verification, initial classification and assignment.
To implement triage in your incident handling process, you can consider your incidents in the same way a doctor thinks about patients. You will need to complete the triage process to prioritise the incident and progress it to diagnosis and resolution. The triage should determine the:
- significance of the constituency
- experience of the incident reporter
- severity of the incident
- time constraints.
The basic questions that should be answered in this phase are:
- Is it really an IT security incident?
- Is it related to one of your constituents?
- Does it fit within the mandate the CERT has?
- What is the impact?
- Is there collateral damage?
- How fast could it spread to other constituents?
- How many people do you need to handle this incident?
- Which incident handler should be appointed to the incident?
This information allows you to decide what to do. Should you reject the incident, should you undertake immediate action or can you perhaps handle the incident later? You can also decide that just advice is enough at this moment because the incident was reported by an experienced user (you know him). Eventually you may skip handling completely if your triage process tells you the issue is not important at all.
Root Cause Analysis
Root cause analysis (RCA) is a method of problem solving used for identifying the root causes of faults or problems. A factor is considered a root cause if removal thereof from the problem-fault-sequence prevents the final undesirable event from recurring; whereas a causal factor is one that affects an event’s outcome, but is not a root cause. Though removing a causal factor can benefit an outcome, it does not prevent its recurrence within certainty.
For example, imagine an investigation into a machine that stopped because it overloaded and the fuse blew. Investigation shows that the machine overloaded because it had a bearing that wasn’t being sufficiently lubricated. The investigation proceeds further and finds that the automatic lubrication mechanism had a pump which was not pumping sufficiently, hence the lack of lubrication. Investigation of the pump shows that it has a worn shaft. Investigation of why the shaft was worn discovers that there isn’t an adequate mechanism to prevent metal scrap getting into the pump. This enabled scrap to get into the pump, and damage it. The root cause of the problem is therefore that metal scrap can contaminate the lubrication system. Fixing this problem ought to prevent the whole sequence of events recurring. Compare this with an investigation that does not find the root cause: replacing the fuse, the bearing, or the lubrication pump will probably allow the machine to go back into operation for a while. But there is a risk that the problem will simply recur, until the root cause is dealt with.
The primary aim of root cause analysis is: to identify the factors that resulted in the nature, the magnitude, the location, and the timing of the harmful outcomes (consequences) of one or more past events; to determine what behaviors, actions, inactions, or conditions need to be changed; to prevent recurrence of similar harmful outcomes; and to identify lessons that may promote the achievement of better consequences. (“Success” is defined as the near-certain prevention of recurrence.)
To be effective, root cause analysis must be performed systematically, usually as part of an investigation, with conclusions and root causes that are identified backed up by documented evidence. A team effort is typically required.
There may be more than one root cause for an event or a problem, wherefore the difficult part is demonstrating the persistence and sustaining the effort required to determine them. The purpose of identifying all solutions to a problem is to prevent recurrence at lowest cost in the simplest way. If there are alternatives that are equally effective, then the simplest or lowest cost approach is preferred.
The root causes identified will depend on the way in which the problem or event is defined. Effective problem statements and event descriptions (as failures, for example) are helpful and usually required to ensure the execution of appropriate analyses.
One logical way to trace down root causes is by utilizing hierarchical clustering data-mining solutions (such as graph-theory-based data mining). A root cause is defined in that context as “the conditions that enable one or more causes”. Root causes can be deductively sorted out from upper groups of which the groups include a specific cause.
To be effective, the analysis should establish a sequence of events or timeline for understanding the relationships between contributory (causal) factors, root cause(s) and the defined problem or event to be prevented.
Root cause analysis can help transform a reactive culture (one that reacts to problems) into a forward-looking culture (one that solves problems before they occur or escalate). More importantly, RCA reduces the frequency of problems occurring over time within the environment where the process is used.
Root cause analysis as a force for change is a threat to many cultures and environments. Threats to cultures are often met with resistance. Other forms of management support may be required to achieve effectiveness and success with root cause analysis. For example, a “non-punitive” policy toward problem identifiers may be required.
