The solution to expanding Hadoop clusters indefinitely is to federate the NameNode. Before Hadoop 2 entered the scene, Hadoop clusters had to live with the fact that NameNode placed limits on the degree to which they could scale. Few clusters were able to scale beyond 3,000 or 4,000 nodes.
NameNode’s need to maintain records for every block of data stored in the cluster turned out to be the most significant factor restricting greater cluster growth. When you have too many blocks, it becomes increasingly difficult for the NameNode to scale up as the Hadoop cluster scales out.
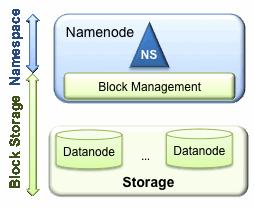
The prior HDFS architecture allows only a single namespace for the entire cluster. In that configuration, a single Namenode manages the namespace. HDFS Federation addresses this limitation by adding support for multiple Namenodes/namespaces to HDFS.
Multiple Namenodes/Namespaces
In order to scale the name service horizontally, federation uses multiple independent Namenodes/namespaces. The Namenodes are federated; the Namenodes are independent and do not require coordination with each other. The Datanodes are used as common storage for blocks by all the Namenodes. Each Datanode registers with all the Namenodes in the cluster. Datanodes send periodic heartbeats and block reports. They also handle commands from the Namenodes.
Users may use ViewFs to create personalized namespace views. ViewFs is analogous to client side mount tables in some Unix/Linux systems.
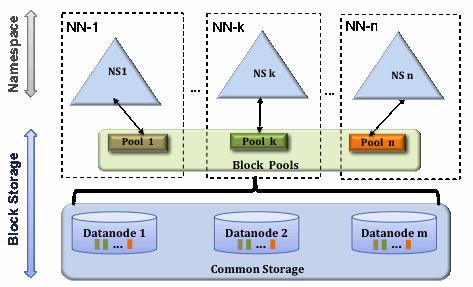
Block Pool – A Block Pool is a set of blocks that belong to a single namespace. Datanodes store blocks for all the block pools in the cluster. Each Block Pool is managed independently. This allows a namespace to generate Block IDs for new blocks without the need for coordination with the other namespaces. A Namenode failure does not prevent the Datanode from serving other Namenodes in the cluster.
A Namespace and its block pool together are called Namespace Volume. It is a self-contained unit of management. When a Namenode/namespace is deleted, the corresponding block pool at the Datanodes is deleted. Each namespace volume is upgraded as a unit, during cluster upgrade.
ClusterID – A ClusterID identifier is used to identify all the nodes in the cluster. When a Namenode is formatted, this identifier is either provided or auto generated. This ID should be used for formatting the other Namenodes into the cluster.
Key Benefits
- Namespace Scalability – Federation adds namespace horizontal scaling. Large deployments or deployments using lot of small files benefit from namespace scaling by allowing more Namenodes to be added to the cluster.
- Performance – File system throughput is not limited by a single Namenode. Adding more Namenodes to the cluster scales the file system read/write throughput.
- Isolation – A single Namenode offers no isolation in a multi user environment. For example, an experimental application can overload the Namenode and slow down production critical applications. By using multiple Namenodes, different categories of applications and users can be isolated to different namespaces.
Federation Configuration
Federation configuration is backward compatible and allows existing single Namenode configurations to work without any change. The new configuration is designed such that all the nodes in the cluster have the same configuration without the need for deploying different configurations based on the type of the node in the cluster.
Federation adds a new NameServiceID abstraction. A Namenode and its corresponding secondary/backup/checkpointer nodes all belong to a NameServiceId. In order to support a single configuration file, the Namenode and secondary/backup/checkpointer configuration parameters are suffixed with the NameServiceID.
Configuration:
Step 1: Add the dfs.nameservices parameter to your configuration and configure it with a list of comma separated NameServiceIDs. This will be used by the Datanodes to determine the Namenodes in the cluster.
Step 2: For each Namenode and Secondary Namenode/BackupNode/Checkpointer add the following configuration parameters suffixed with the corresponding NameServiceID into the common configuration file:
| Daemon | Configuration Parameter |
| Namenode | dfs.namenode.rpc-address dfs.namenode.servicerpc-address dfs.namenode.http-address dfs.namenode.https-address dfs.namenode.keytab.file dfs.namenode.name.dir dfs.namenode.edits.dir dfs.namenode.checkpoint.dir dfs.namenode.checkpoint.edits.dir |
| Secondary Namenode | dfs.namenode.secondary.http-address dfs.secondary.namenode.keytab.file |
| BackupNode | dfs.namenode.backup.address dfs.secondary.namenode.keytab.file |
Formatting the NameNode
Step 1: A single name node can be formatted using the following:
$HADOOP_USER_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
The cluster id should be unique and must not conflict with any other exiting cluster id. If not provided, a unique cluster id is generated at the time of formatting.
Step 2: Additional NameNode can be formatted using the following command:
$HADOOP_PREFIX_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
It is important that the cluster id mentioned here should be the same of that mentioned in the step 1. If these two are different, the additional NameNode won’t be the part of the federated cluster.
Starting and stopping the cluster
Check the commands to start and stop the cluster.
Start the cluster – The cluster can be started by executing the following command –
$HADOOP_PREFIX_HOME/bin/start-dfs.sh
Stop the cluster – The cluster can be stopped by executing the following command –
$HADOOP_PREFIX_HOME/bin/start-dfs.sh
Add a new namenode to an existing cluster
We have already described that multiple NameNodes are at the heart of Hadoop Federation. So it is important to understand the steps to add new NameNodes and scale horizontally. The following steps are needed to add new NameNodes
- The configuration parameter – dfs.nameservices needs to be added in the configuration.
- NameServiceID must be suffixed in the configuration
- New Namenode related to the config must be added in the configuration files.
- The configuration file should be propagated to all the nodes in the cluster.
- Start the new NameNode and the secondary NameNode
- Refresh the other DataNodes to pick the newly added NameNode by running the following command:
- $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
- The above command must be executed against all DataNodes on the cluster.
