Analysis of variance (ANOVA) is a collection of statistical models used to analyze the differences among group means and their associated procedures (such as “variation” among and between groups). The observed variance in a particular variable is partitioned into components attributable to different sources of variation. In its simplest form, ANOVA provides a statistical test of whether or not the means of several groups are equal, and therefore generalizes the t-test to more than two groups. As doing multiple two-sample t-tests would result in an increased chance of committing a statistical type I error, ANOVAs are useful for comparing (testing) three or more means (groups or variables) for statistical significance.
ANOVA is a particular form of statistical hypothesis testing heavily used in the analysis of experimental data. A test result (calculated from the null hypothesis and the sample) is called statistically significant if it is deemed unlikely to have occurred by chance, assuming the truth of the null hypothesis. A statistically significant result, when a probability (p-value) is less than a threshold (significance level), justifies the rejection of the null hypothesis, but only if the a priori probability of the null hypothesis is not high.
In the typical application of ANOVA, the null hypothesis is that all groups are simply random samples of the same population. For example, when studying the effect of different treatments on similar samples of patients, the null hypothesis would be that all treatments have the same effect (perhaps none). Rejecting the null hypothesis would imply that different treatments result in altered effects.
By construction, hypothesis testing limits the rate of Type I errors (false positives) to a significance level. Experimenters also wish to limit Type II errors (false negatives). The rate of Type II errors depends largely on too small of sample size, significance level (when the standard of proof is high, the chances of overlooking a discovery are also high) and effect size.
The reason for doing an ANOVA is to see if there is any difference between groups on some variable. For example, you might have data on student performance in non-assessed tutorial exercises as well as their final grading. You are interested in seeing if tutorial performance is related to final grade. ANOVA allows you to break up the group according to the grade and then see if performance is different across these grades. ANOVA is available for both parametric (score data) and non-parametric (ranking/ordering) data.
Types of ANOVA
One-way between groups – The example given above is called a one-way between groups model. You are looking at the differences between the groups. There is only one grouping (final grade) which you are using to define the groups. This is the simplest version of ANOVA. This type of ANOVA can also be used to compare variables between different groups – tutorial performance from different intakes.
One-way repeated measures – A one way repeated measures ANOVA is used when you have a single group on which you have measured something a few times. For example, you may have a test of understanding of Classes. You give this test at the beginning of the topic, at the end of the topic and then at the end of the subject. You would use a one-way repeated measures ANOVA to see if student performance on the test changed over time.
Two-way between groups – A two-way between groups ANOVA is used to look at complex groupings. For example, the grades by tutorial analysis could be extended to see if overseas students performed differently to local students. What you would have from this form of ANOVA is
- The effect of final grade
- The effect of overseas versus local
- The interaction between final grade and overseas/local
Each of the main effects are one-way tests. The interaction effect is simply asking “is there any significant difference in performance when you take final grade and overseas/local acting together”.
Two-way repeated measures – This version of ANOVA simple uses the repeated measures structure and includes an interaction effect. In the example given for one-way between groups, you could add Gender and see if there was any joint effect of gender and time of testing – i.e. do males and females differ in the amount they remember/absorb over time.
Example
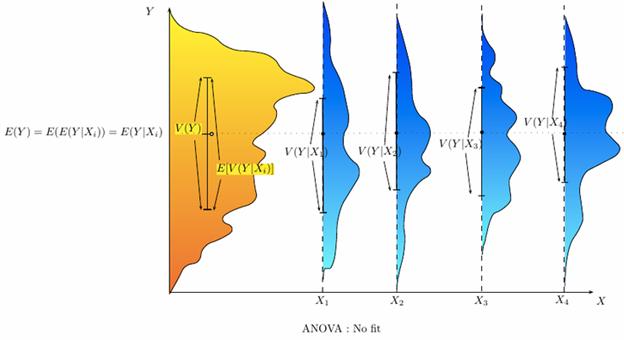
The analysis of variance can be used as an exploratory tool to explain observations. A dog show provides an example. A dog show is not a random sampling of the breed: it is typically limited to dogs that are adult, pure-bred, and exemplary. A histogram of dog weights from a show might plausibly be rather complex, like the yellow-orange distribution shown in the illustrations. Suppose we wanted to predict the weight of a dog based on a certain set of characteristics of each dog. Before we could do that, we would need to explain the distribution of weights by dividing the dog population into groups based on those characteristics. A successful grouping will split dogs such that (a) each group has a low variance of dog weights (meaning the group is relatively homogeneous) and (b) the mean of each group is distinct (if two groups have the same mean, then it isn’t reasonable to conclude that the groups are, in fact, separate in any meaningful way).
In the illustrations, each group is identified as X1, X2, etc. In the first illustration, we divide the dogs according to the product (interaction) of two binary groupings: young vs old, and short-haired vs long-haired (thus, group 1 is young, short-haired dogs, group 2 is young, long-haired dogs, etc.). Since the distributions of dog weight within each of the groups (shown in blue) has a large variance, and since the means are very close across groups, grouping dogs by these characteristics does not produce an effective way to explain the variation in dog weights: knowing which group a dog is in does not allow us to make any reasonable statements as to what that dog’s weight is likely to be. Thus, this grouping fails to fit the distribution we are trying to explain (yellow-orange).
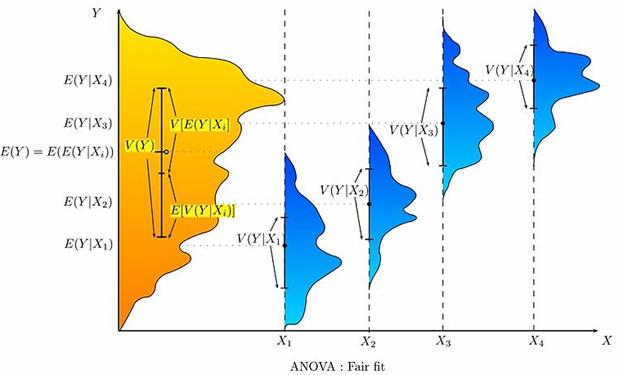
An attempt to explain the weight distribution by grouping dogs as (pet vs working breed) and (less athletic vs more athletic) would probably be somewhat more successful (fair fit). The heaviest show dogs are likely to be big strong working breeds, while breeds kept as pets tend to be smaller and thus lighter. As shown by the second illustration, the distributions have variances that are considerably smaller than in the first case, and the means are more reasonably distinguishable. However, the significant overlap of distributions, for example, means that we cannot reliably say that X1 and X2 are truly distinct (i.e., it is perhaps reasonably likely that splitting dogs according to the flip of a coin—by pure chance—might produce distributions that look similar).
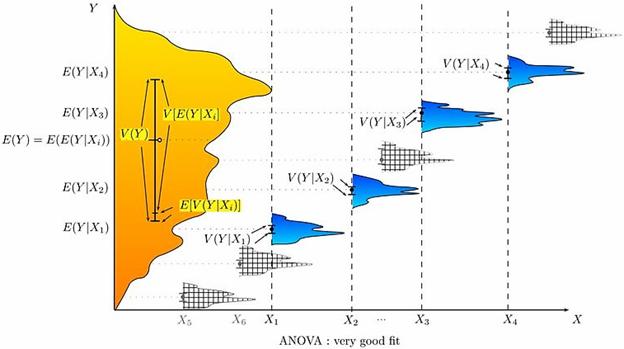
An attempt to explain weight by breed is likely to produce a very good fit. All Chihuahuas are light and all St Bernards are heavy. The difference in weights between Setters and Pointers does not justify separate breeds. The analysis of variance provides the formal tools to justify these intuitive judgments. A common use of the method is the analysis of experimental data or the development of models. The method has some advantages over correlation: not all of the data must be numeric and one result of the method is a judgment in the confidence in an explanatory relationship.
Classes of Models
There are three classes of models used in the analysis of variance, and these are outlined here.
- Fixed-effects models – The fixed-effects model (class I) of analysis of variance applies to situations in which the experimenter applies one or more treatments to the subjects of the experiment to see whether the response variable values change. This allows the experimenter to estimate the ranges of response variable values that the treatment would generate in the population as a whole.
- Random-effects models – Random effects model (class II) is used when the treatments are not fixed. This occurs when the various factor levels are sampled from a larger population. Because the levels themselves are random variables, some assumptions and the method of contrasting the treatments (a multi-variable generalization of simple differences) differ from the fixed-effects model.
- Mixed-effects models – A mixed-effects model (class III) contains experimental factors of both fixed and random-effects types, with appropriately different interpretations and analysis for the two types. Example: Teaching experiments could be performed by a university department to find a good introductory textbook, with each text considered a treatment. The fixed-effects model would compare a list of candidate texts. The random-effects model would determine whether important differences exist among a list of randomly selected texts. The mixed-effects model would compare the (fixed) incumbent texts to randomly selected alternatives.
Defining fixed and random effects has proven elusive, with competing definitions arguably leading toward a linguistic quagmire.
Characteristics of ANOVA
ANOVA is used in the analysis of comparative experiments, those in which only the difference in outcomes is of interest. The statistical significance of the experiment is determined by a ratio of two variances. This ratio is independent of several possible alterations to the experimental observations: Adding a constant to all observations does not alter significance. Multiplying all observations by a constant does not alter significance. So ANOVA statistical significance result is independent of constant bias and scaling errors as well as the units used in expressing observations. In the era of mechanical calculation it was common to subtract a constant from all observations (when equivalent to dropping leading digits) to simplify data entry. This is an example of data coding.
