 Stay Ahead with the Power of Upskilling - Invest in Yourself!
Stay Ahead with the Power of Upskilling - Invest in Yourself! 
Certify and Increase Opportunity.
Be
Govt. Certified Apache Cassandra Professional
Bloom Filter in Apache Cassandra
Bloom filters are compact data structures for probabilistic representation of a set in order to support membership queries. Each filter provides a constant-space approximate representation of the contents of a set. Errors between the actual set and the Bloom filter representation are always of the form of false positives to inclusion tests. A Bloom filter is a bit vector, and items are inserted by setting the bits corresponding to a number of independent hash functions.
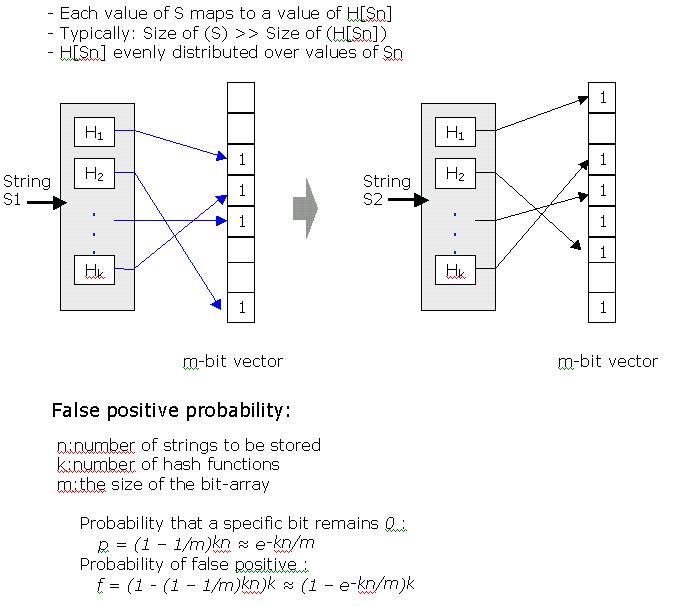
Bloom filters apply better to data classified and represented by scalars. This project aims to create Bloom filter representation for encoding hierarchical data. There are some efforts on Attenuated Bloom Filter, and you can use it as base or create your own design.
Bloom Filter in Cassandra
In Cassandra when data is requested, the Bloom filter checks if the requested row exists in the SSTable before doing any disk I/O. High memory consumption can result from the Bloom filter false positive ratio being set too low. The higher the Bloom filter setting, the lower the memory consumption. By tuning a Bloom filter, you are setting the chance of false positives; the lower the chances of false positives, the larger the Bloom filter. The maximum recommended setting is 0.1, as anything above this value yields diminishing returns.
Bloom filter settings range from 0.000744 (default) to 1.0 (disabled). For example, to run an analytics application that heavily scans a particular column family, you would want to inhibit the Bloom filter on the column family by setting it high. Setting it high ensures that an analytics application will never ask for keys that don’t exist.
To change the Bloom filter attribute on a column family, use CQL. For example:
ALTER TABLE addamsFamily WITH bloom_filter_fp_chance = 0.01;
After updating the value of bloom_filter_fp_chance on a column family, Bloom filters need to be regenerated in one of these ways:
Initiate compaction
Upgrade SSTables
You do not have to restart Cassandra after regenerating SSTables.
Tombstones in Apache Cassandra
A tombstone is a deleted record in a replica of a distributed data store. The tombstone is necessary, as distributed data stores use eventual consistency, where only a subset of nodes where the data is stored must respond before an operation is considered to be successful.
In Apache Cassandra, this elapsed time is set with the GCGraceSeconds parameter.
A Cassandra cluster defines a ReplicationFactor that determines how many nodes each key and associated columns are written to. In Cassandra (as in Dynamo), the client controls how many replicas to block for on writes, which includes deletions. In particular, the client may, and typically will, specify a ConsistencyLevel of less than the cluster’s ReplicationFactor, that is, the coordinating server node should report the write successful even if some replicas are down or otherwise not responsive to the write.
(Thus, the “eventual” in eventual consistency: if a client reads from a replica that did not get the update with a low enough ConsistencyLevel, it will potentially see old data. Cassandra uses HintedHandoff, ReadRepair, and AntiEntropy to reduce the inconsistency window, as well as offering higher consistency levels such as ConstencyLevel.QUORUM, but it’s still something we have to be aware of.)
Thus, a delete operation can’t just wipe out all traces of the data being removed immediately: if we did, and a replica did not receive the delete operation, when it becomes available again it will treat the replicas that did receive the delete as having missed a write update, and repair them! So, instead of wiping out data on delete, Cassandra replaces it with a special value called a tombstone. The tombstone can then be propagated to replicas that missed the initial remove request.
There’s one more piece to the problem: how do we know when it’s safe to remove tombstones? In a fully distributed system, we can’t. We could add a coordinator like ZooKeeper, but that would pollute the simplicity of the design, as well as complicating ops — then you’d essentially have two systems to monitor, instead of one. (This is not to say ZK is bad software — I believe it is best in class at what it does — only that it solves a problem that we do not wish to add to our system.)
So, Cassandra does what distributed systems designers frequently do when confronted with a problem we don’t know how to solve: define some additional constraints that turn it into one that we do. Here, we defined a constant, GCGraceSeconds, and had each node track tombstone age locally. Once it has aged past the constant, it can be GC’d during compaction (see MemtableSSTable). This means that if you have a node down for longer than GCGraceSeconds, you should treat it as a failed node and replace it as described in Operations. The default setting is very conservative, at 10 days; you can reduce that once you have Anti Entropy configured to your satisfaction. And of course if you are only running a single Cassandra node, you can reduce it to zero, and tombstones will be GC’d at the first major compaction. Since 0.6.8, minor compactions also GC tombstones.
Apply for Apache Cassandra Certification Now!!
http://www.vskills.in/certification/Certified-Apache-Cassandra-Professional
