Hadoop is a part of a larger framework of related technologies
- HDFS – Hadoop Distributed File System
- HBase – Column oriented, non-relational, schema-less, distributed database modeled after Google’s BigTable. Promises “Random, real-time read/write access to Big Data”
- Hive – Data warehouse system that provides SQL interface. Data structure can be projected ad hoc onto unstructured underlying data
- Pig – A platform for manipulating and analyzing large data sets. High level language for analysts
- ZooKeeper – a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services
At its core, Hadoop is comprised of four things:
- Hadoop Common- A set of common libraries and utilities used by other Hadoop modules.
- HDFS- The default storage layer for Hadoop.
- MapReduce- Executes a wide range of analytic functions by analysing datasets in parallel before ‘reducing’ the results. The “Map” job distributes a query to different nodes, and the “Reduce” gathers the results and resolves them into a single value.
- YARN- Present in version 2.0 onwards, YARN is the cluster management layer of Hadoop. Prior to 2.0, MapReduce was responsible for cluster management as well as processing. The inclusion of YARN means you can run multiple applications in Hadoop (so you’re no longer limited to MapReduce), which all share common cluster management.
These four components form the basic Hadoop framework. However, a vast array of other components have emerged, aiming to ameliorate Hadoop in some way- whether that be making Hadoop faster, better integrating it with other database solutions or building in new capabilities. Some the more well-known components include
- Spark- Used on top of HDFS, Spark promises speeds up to 100 times faster than the two-step MapReduce function in certain applications. Allows data to loaded in-memory and queried repeatedly, making it particularly apt for machine learning algorithms
- Hive- Originally developed by Facebook, Hive is a data warehouse infrastructure built on top of Hadoop. Hive provides a simple, SQL-like language called HiveQL, whilst maintaining full support for MapReduce. This means SQL programmers with little former experience with Hadoop can use the system easier, and provides better integration with certain analytics packages like Tableau. Hive also provides indexes, making querying faster.
- HBase- Is a NoSQL columnar database which is designed to run on top of HDFS. It is modelled after Google’s BigTable and written in Java. It was designed to provide BigTable-like capabilities to Hadoop, such as the columnar data storage model and storage for sparse data.
- Flume- Flume collects (typically log) data from ‘agents’ which it then aggregates and moves into Hadoop. In essence, Flume is what takes the data from the source (say a server or mobile device) and delivers it to Hadoop.
- Mahout- Mahout is a machine learning library. It collects key algorithms for clustering, classification and collaborative filtering and implements them on top of distributed data systems, like MapReduce. Mahout primarily set out to collect algorithms for implementation on the MapReduce model, but has begun implementing on other systems which were more efficient for data mining, such as Spark.
- Sqoop- Sqoop is a tool which aids in transitioning data from other database systems (such as relational databases) into Hadoop.
- Ambari – Hadoop management and monitoring
- Avro – Data serialization system
- Chukwa – Data collection and monitoring
- Hue – Hadoop web interface for analyzing data
- Storm – Distributed real-time computation system
Hadoop 1 Architecture
Hadoop 1 popularized MapReduce programming for batch jobs and demonstrated the potential value of large scale, distributed processing. MapReduce, as implemented in Hadoop 1, can be I/O intensive, not suitable for interactive analysis, and constrained in support for graph, machine learning and on other memory intensive algorithms. Hadoop developers rewrote major components of the file system to produce Hadoop 2. In the Hadoop 1 architecture, a master Job Tracker is used to manage Task Trackers on slave nodes. Hadoop’s data node and Task Trackers co-exist on the same slave nodes.
The cluster-level Job Tracker handles client requests via a Map Reduce (MR) API. The clients need only process via the MR API, as the Map Reduce framework and system handle the scheduling, resources, and failover in the event of a crash. Job Tracker handles jobs via data node–based Task Trackers that manage the actual tasks or processes. Job Tracker manages the whole client-requested job, passing subtasks to individual slave nodes and monitoring their availability and the tasks’ completion.
It can be visualized as –
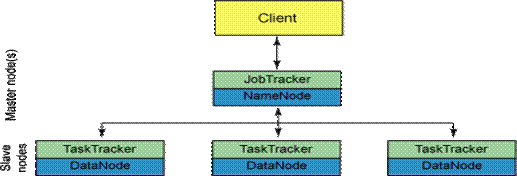
A Hadoop cluster can be divided into two abstract entities: a MapReduce engine and a distributed file system. The MapReduce engine provides the ability to execute map and reduce tasks across the cluster and report results where the distributed file system provides a storage scheme that can replicate data across nodes for processing. The Hadoop distributed file system (HDFS) was defined to support large files (where files are commonly multiples of 64 MB each).
When a client makes a request of a Hadoop cluster, this request is managed by the JobTracker. The JobTracker, working with the NameNode, distributes work as closely as possible to the data on which it will work. The NameNode is the master of the file system, providing metadata services for data distribution and replication. The JobTracker schedules map and reduce tasks into available slots at one or more TaskTrackers. The TaskTracker, working with the DataNode (the slave portions of the distributed file system) to execute map and reduce tasks on data from the DataNode. When the map and reduce tasks are complete, the TaskTracker notifies the JobTracker, which identifies when all tasks are complete and eventually notifies the client of job completion.
As in the figure above, MRv1 or MapReduce version 1, implements a relatively straightforward cluster manager for MapReduce processing. MRv1 provides a hierarchical scheme for cluster management in which big data jobs filter into a cluster as individual map and reduce tasks and eventually aggregate back up to job reporting to the user. But in this simplicity lies some hidden and not-so-hidden problems.
Inadequacy of Hadoop 1 – This architecture does have inadequacies, mostly coming into play for large clusters. As clusters exceeded 4,000 nodes (where each node could be multicore), some amount of unpredictability surfaced. One of the biggest issues was cascading failures, where the failure resulted in a serious deterioration of the overall cluster because of attempts to replicate data and overload live nodes, through network flooding.
But the biggest issue is multi-tenancy. As clusters increase in size, it’s desirable to employ these clusters for a variety of models and to re-purpose them for other applications and workloads. As big data and Hadoop become an even more important use model for cloud deployments, this capability will increase because it permits physicalization of Hadoop on servers compared to the requirement of virtualization and its added management, computational, and input/output overhead.
Hadoop 2 Architecture
To enable greater sharing, scalability, and reliability of a Hadoop cluster, designers took a hierarchical approach to the cluster framework. In particular, the MapReduce-specific functionality has been replaced with a new set of daemons that opens the framework to new processing models.
JobTracker and TaskTracker approach was a central focus of the deficiencies because of its limiting of scaling and certain failure modes caused by network overhead. These daemons were also specific to the MapReduce processing model. To remove that dependency, the JobTracker and TaskTracker have been removed from YARN and replaced with a new set of daemons that are agnostic to the application.
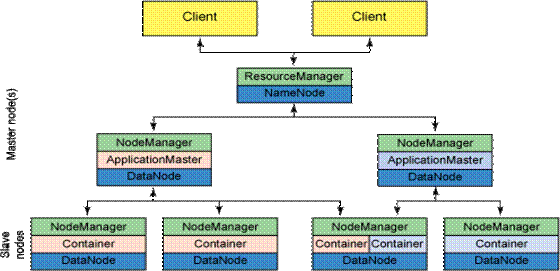
At the root of a YARN hierarchy is the ResourceManager. This entity governs an entire cluster and manages the assignment of applications to underlying compute resources. The ResourceManager orchestrates the division of resources (compute, memory, bandwidth, etc.) to underlying NodeManagers (YARN’s per-node agent). The ResourceManager also works with ApplicationMasters to allocate resources and work with the NodeManagers to start and monitor their underlying application. In this context, the ApplicationMaster has taken some of the role of the prior TaskTracker, and the ResourceManager has taken the role of the JobTracker.
An ApplicationMaster manages each instance of an application that runs within YARN. The ApplicationMaster is responsible for negotiating resources from the ResourceManager and, through the NodeManager, monitoring the execution and resource consumption of containers (resource allocations of CPU, memory, etc.). Note that although resources today are more traditional (CPU cores, memory), tomorrow will bring new resource types based on the task at hand (for example, graphical processing units or specialized processing devices). From the perspective of YARN, ApplicationMasters are user code and therefore a potential security issue. YARN assumes that ApplicationMasters are buggy or even malicious and therefore treats them as unprivileged code.
The NodeManager manages each node within a YARN cluster. The NodeManager provides per-node services within the cluster, from overseeing the management of a container over its life cycle to monitoring resources and tracking the health of its node. Unlike MRv1, which managed execution of map and reduce tasks via slots, the NodeManager manages abstract containers, which represent per-node resources available for a particular application. YARN continues to use the HDFS layer, with its master NameNode for metadata services and DataNode for replicated storage services across a cluster.
Use of a YARN cluster begins with a request from a client consisting of an application. The ResourceManager negotiates the necessary resources for a container and launches an ApplicationMaster to represent the submitted application. Using a resource-request protocol, the ApplicationMaster negotiates resource containers for the application at each node. Upon execution of the application, the ApplicationMaster monitors the container until completion. When the application is complete, the ApplicationMaster unregisters its container with the ResourceManager, and the cycle is complete.
The older Hadoop architecture was highly constrained through the JobTracker, which was responsible for resource management and scheduling jobs across the cluster. The new YARN architecture breaks this model, allowing a new ResourceManager to manage resource usage across applications, with ApplicationMasters taking the responsibility of managing the execution of jobs. This change removes a bottleneck and also improves the ability to scale Hadoop clusters to much larger configurations than previously possible. In addition, beyond traditional MapReduce, YARN permits simultaneous execution of a variety of programming models, including graph processing, iterative processing, machine learning, and general cluster computing, using standard communication schemes like the Message Passing Interface.
Two of the most important advances in Hadoop 2 are the introduction of HDFS federation and the resource manager YARN.
YARN is a resource manager that was created by separating the processing engine and resource management capabilities of MapReduce as it was implemented in Hadoop 1. YARN is often called the operating system of Hadoop because it is responsible for managing and monitoring workloads, maintaining a multi-tenant environment, implementing security controls, and managing high availability features of Hadoop.
With YARN, Hadoop V2’s Job Tracker has been split into a master Resource Manager and slave-based Application Master processes. It separates the major tasks of the Job Tracker: resource management and monitoring/scheduling. The Job History server now has the function of providing information about completed jobs. The Task Tracker has been replaced by a slave-based Node Manager, which handles slave node–based resources and manages tasks on the node. The actual tasks reside within containers launched by the Node Manager. The Map Reduce function is controlled by the Application Master process, while the tasks themselves may be either Map or Reduce tasks. Hadoop V2 also offers the ability to use non-Map Reduce processing, like Apache Giraph for graph processing, or Impala for data query. Resources on YARN can be shared among all three processing systems.
HDFS federation brings important measures of scalability and reliability to Hadoop. It generalizes the storage model in Hadoop 2.X. The block storage layer has been generalized and separated out from the filesystem layer. This separation has given an opening for other storage services to be integrated into a Hadoop cluster. Previously, HDFS and the block storage layer were tightly coupled. Federation allows multiple HDFS namespaces to use the same underlying storage. Federated NameNodes provide isolation at the filesystem level.
Like an operating system on a server, YARN is designed to allow multiple, diverse user applications to run on a multi-tenant platform. In Hadoop 1, users had the option of writing MapReduce programs in Java, in Python, Ruby or other scripting languages using streaming, or using Pig, a data transformation language. Regardless of which method was used, all fundamentally relied on the MapReduce processing model to run.
YARN supports multiple processing models in addition to MapReduce. One of the most significant benefits of this is that we are no longer limited to working the often I/O intensive, high latency MapReduce framework. This advance means Hadoop users should be familiar with the pros and cons of the new processing models and understand when to apply them to particular use cases.
Both can be compared as below
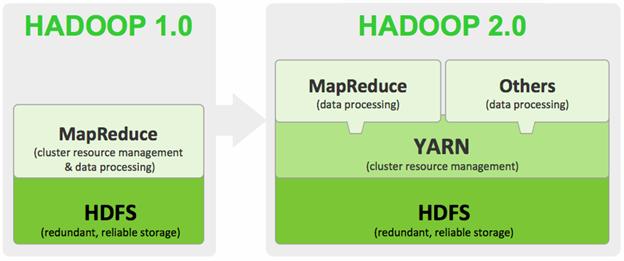
Other enhancements in Hadoop 2 include –
- The wire protocol for RPCs within Hadoop is now based on Protocol Buffers. Previously, Java serialization via Writables was used.
- HDFS in Hadoop 1.X was agnostic about the type of storage being used. Mechanical or SSD drives were treated uniformly. Hadoop 2.X releases in 2014 are aware of the type of storage and expose this information to applications as well.
- HDFS snapshots are point-in-time, read-only images of the entire or a particular subset of a filesystem, taken for protection against user errors or backup or disaster recovery
To illustrate the efficiency of YARN over MRv1, consider the parallel problem of brute-forcing the old LAN Manager Hash that older Windows® incarnations used for password hashing. In this scenario, the MapReduce method makes little sense, because too much overhead is involved in the mapping/reducing stages. Instead, it’s more logical to abstract the distribution so that each container has a piece of the password search space, enumerate over it, and notify you if the proper password is found. The point here is that the password would be determined dynamically through a function (really just bit flipping) vs. needing to map all possibilities into a data structure, making the MapReduce style unnecessary and unwieldy.
With the new power that YARN provides and the capabilities to build custom application frameworks on top of Hadoop, you also get new complexity. Building applications for YARN is considerably more complex than building traditional MapReduce applications on top of pre-YARN Hadoop because you need to develop an ApplicationMaster, which is the ResourceManager launches when a client request arrives. The ApplicationMaster has several requirements, including implementation of a number of required protocols to communicate with the ResourceManager (for requesting resources) and NodeManager (to allocate containers). For existing MapReduce users, a MapReduce ApplicationMaster minimizes any new work required, making the amount of work required to deploy MapReduce jobs similar to pre-YARN Hadoop.
Map Reduce Work Flow
MapReduce is the heart of hadoop. It is a programming model designed for processing large volumes of data in parallel by dividing the work into a set of independent tasks. The framework possesses the feature of data locality. Data locality means movement of algorithm to the data instead of data to algorithm. When the processing is done on the data algorithm is moved across the DataNodes rather than data to the algorithm. The architecture is so constructed because moving computation is cheaper than moving data.
It is fault tolerant which is achieved by its daemons using the concept of replication. The daemons associated with the MapReduce phase are job-tracker and task-trackers. Map-Reduce jobs are submitted on job-tracker. The JobTracker pushes work out to available TaskTracker nodes in the cluster, striving to keep the work as close to the data as possible. A heartbeat is sent from the TaskTracker to the JobTracker every few minutes to check its status whether the node is dead or alive. Whenever there is negative status, the job tracker assigns the task to another node on the replicated data of the failed node stored in this node. MapReduce has a simple model of data processing: inputs and outputs for the map and reduce functions are key-value pairs. The map and reduce functions in Hadoop MapReduce have the following general form:
map: (K1, V1) → list(K2, V2)
reduce: (K2, list(V2)) → list(K3, V3)
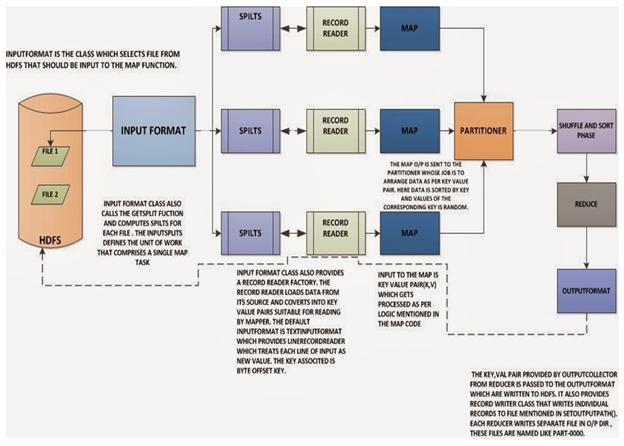
Now before processing it needs to know on which data to process, this is achieved with the InputFormat class. InputFormat is the class which selects file from HDFS that should be input to the map function. An InputFormat is also responsible for creating the input splits and dividing them into records. The data is divided into number of splits(typically 64/128mb) in HDFS. An input split is a chunk of the input that is processed by a single map.
InputFormat class calls the getSplits() function and computes splits for each file and then sends them to the jobtracker, which uses their storage locations to schedule map tasks to process them on the tasktrackers. On a tasktracker, the map task passes the split to the createRecordReader() method on InputFormat to obtain a RecordReader for that split. The RecordReader loads data from its source and converts into key-value pairs suitable for reading by mapper. The default InputFormat is TextInputFormat which treats each value of input a new value and the associated key is byte offset.
A RecordReader is little more than an iterator over records, and the map task uses one to generate record key-value pairs, which it passes to the map function. We can see this by looking at the Mapper’s run() method:
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
After running setup(), the nextKeyValue() is called repeatedly on the Context, (which delegates to the identically-named method on the RecordReader) to populate the key and value objects for the mapper. The key and value are retrieved from the Record Reader by way of the Context, and passed to the map() method for it to do its work. Input to the map function which is the key-value pair (K, V) gets processed as per the logic mentioned in the map code. When the reader gets to the end of the stream, the nextKeyValue() method returns false, and the map task runs its cleanup() method.
The output of the mapper is sent to the partitioner. Partitioner controls the partitioning of the keys of the intermediate map-outputs. The key (or a subset of the key) is used to derive the partition, typically by a hash function. The total number of partitions is the same as the number of reduce tasks for the job. Hence this controls which of the m reduce tasks the intermediate key (and hence the record) is sent for reduction. The use of partitioners is optional.
All values corresponding to the same key will go the same reducer. Output of the mapper is first written on the local disk for sorting and shuffling process. It is also in the form of key-value pair. And then it is merged and finally given to reducer. MapReduce makes the guarantee that the input to every reducer is sorted by key. The process by which the system performs the sort—and transfers the map outputs to the reducers as inputs—is known as the shuffle. It is said that the shuffle is the heart of MapReduce and is where the “magic” happens.
Output of all mapper goes to all reducer. During the reduce phase, the reduce function is invoked for each key in the sorted output. The output of this phase is written to the output filesystem, typically HDFS. The key-value pair provided as output by reducer is passed to the OutputFormat which are then written to HDFS. It also provides RecordWriter class that writes individual records to the file mentioned in setOutputPath(). Each reducer writes separate file in the output directory and these files are named as part-00000.
One can also use the combiner for the optimization purpose. Combiner is conceptually placed after the map block and it reduces the output particular to that block of map. It is generally termed as mini-reducer. It also reduces the network lag.
