Counters are another advanced and useful feature provided by HBase. Counters allow us to increment a column value with the least overhead by providing a mechanism to treat columns as counters. Using counters enables the potential of real-time accounting and completely takes away the offline batch-oriented logfile analysis.
Normally, incrementing column values requires steps such as locking the row, reading, incrementing, writing the value, and finally releasing the row for other writers. These steps cause a lot of I/O overheads and wait for other writers. Counters avoid all these I/O-centric steps by synchronizing the write operation over a row and incrementing values under a single row lock. Therefore, counters work only with a single row.
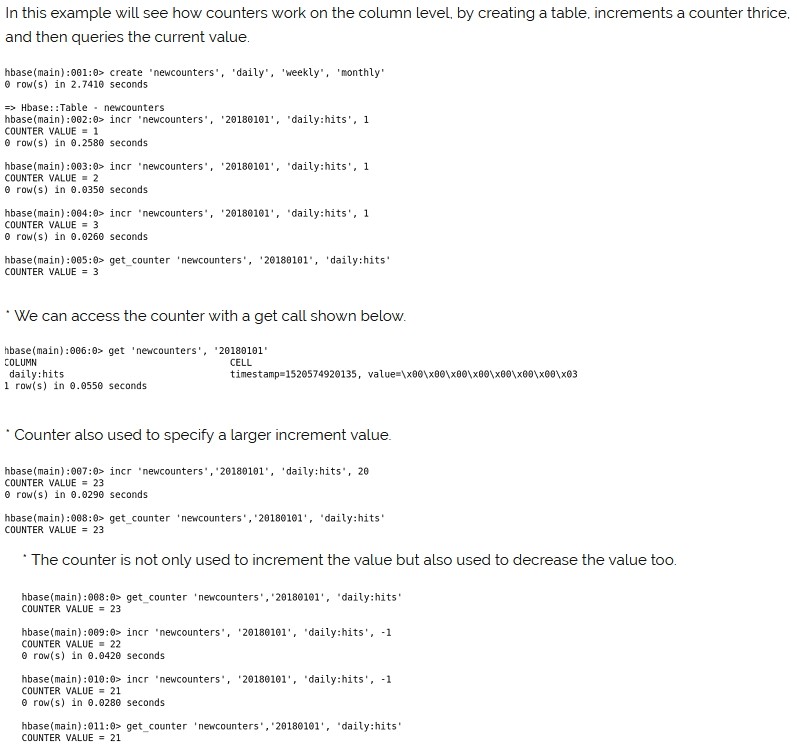
Hbase provides us a mechanism to treat columns as counters. Counters allow us to increment a column value very easily.
When we try to increment a value stored in a table, we should lock the row for long period, to read the value, increment it, write it back to the table then only lock is removed from the row. It causes clash between the clients to access the same row.
This problem is solved is by using counters.
* It is used in analytical systems like digital marketing, click stream analysis and document index model in e-commerce Company.
* Hbase has two types of counter, they are.
Single counter
Multiple counters
Example
Coprocessor
In HBase, you fetch data using a Get or Scan, whereas in an RDBMS you use a SQL query. In order to fetch only the relevant data, you filter it using a HBase Filter , whereas in an RDBMS you use a WHERE predicate.
After fetching the data, you perform computations on it. This paradigm works well for “small data” with a few thousand rows and several columns. However, when you scale to billions of rows and millions of columns, moving large amounts of data across your network will create bottlenecks at the network layer, and the client needs to be powerful enough and have enough memory to handle the large amounts of data and the computations. In addition, the client code can grow large and complex.
In this scenario, coprocessors might make sense. You can put the business computation code into a coprocessor which runs on the RegionServer, in the same location as the data, and returns the result to the client.
This is only one scenario where using coprocessors can provide benefit. Following are some analogies which may help to explain some of the benefits of coprocessors.
Coprocessor Analogies
Triggers and Stored Procedure – An Observer coprocessor is similar to a trigger in a RDBMS in that it executes your code either before or after a specific event (such as a Get or Put) occurs. An endpoint coprocessor is similar to a stored procedure in a RDBMS because it allows you to perform custom computations on the data on the RegionServer itself, rather than on the client.
MapReduce – MapReduce operates on the principle of moving the computation to the location of the data. Coprocessors operate on the same principal.
AOP – If you are familiar with Aspect Oriented Programming (AOP), you can think of a coprocessor as applying advice by intercepting a request and then running some custom code, before passing the request on to its final destination (or even changing the destination).
Coprocessor Implementation
Your class should implement one of the Coprocessor interfaces – Coprocessor, RegionObserver, CoprocessorService – to name a few.
Load the coprocessor, either statically (from the configuration) or dynamically, using HBase Shell.
Call the coprocessor from your client-side code. HBase handles the coprocessor transparently.
The framework API is provided in the coprocessor package.
Types of Coprocessors
Observer Coprocessors – Observer coprocessors are triggered either before or after a specific event occurs. Observers that happen before an event use methods that start with a pre prefix, such as prePut. Observers that happen just after an event override methods that start with a post prefix, such as postPut.
Use Cases for Observer Coprocessors
Security – Before performing a Get or Put operation, you can check for permission using preGet or prePut methods.
Referential Integrity – HBase does not directly support the RDBMS concept of refential integrity, also known as foreign keys. You can use a coprocessor to enforce such integrity. For instance, if you have a business rule that every insert to the users table must be followed by a corresponding entry in the user_daily_attendance table, you could implement a coprocessor to use the prePut method on user to insert a record into user_daily_attendance.
Secondary Indexes – You can use a coprocessor to maintain secondary indexes.
Types of Observer Coprocessor
RegionObserver – A RegionObserver coprocessor allows you to observe events on a region, such as Get and Put operations.
RegionServerObserver – A RegionServerObserver allows you to observe events related to the RegionServer’s operation, such as starting, stopping, or performing merges, commits, or rollbacks.
MasterObserver – A MasterObserver allows you to observe events related to the HBase Master, such as table creation, deletion, or schema modification.
WalObserver – A WalObserver allows you to observe events related to writes to the Write-Ahead Log (WAL).
Examples provides working examples of observer coprocessors.
Endpoint Coprocessor
Endpoint processors allow you to perform computation at the location of the data. An example is the need to calculate a running average or summation for an entire table which spans hundreds of regions.
In contrast to observer coprocessors, where your code is run transparently, endpoint coprocessors must be explicitly invoked using the CoprocessorService() method available in Table or HTable.
Starting with HBase 0.96, endpoint coprocessors are implemented using Google Protocol Buffers (protobuf). Endpoints Coprocessor written in version 0.94 are not compatible with version 0.96 or later. To upgrade your HBase cluster from 0.94 or earlier to 0.96 or later, you need to reimplement your coprocessor.
Coprocessor Endpoints should make no use of HBase internals and only avail of public APIs; ideally a CPEP should depend on Interfaces and data structures only. This is not always possible but beware that doing so makes the Endpoint brittle, liable to breakage as HBase internals evolve. HBase internal APIs annotated as private or evolving do not have to respect semantic versioning rules or general java rules on deprecation before removal. While generated protobuf files are absent the hbase audience annotations — they are created by the protobuf protoc tool which knows nothing of how HBase works — they should be consided @InterfaceAudience.Private so are liable to change.
Examples provides working examples of endpoint coprocessors.
Loading Coprocessors
To make your coprocessor available to HBase, it must be loaded, either statically (through the HBase configuration) or dynamically (using HBase Shell or the Java API).
Static Loading – Follow these steps to statically load your coprocessor. Keep in mind that you must restart HBase to unload a coprocessor that has been loaded statically.
Define the Coprocessor in hbase-site.xml, with a <property> element with a <name> and a <value> sub-element. The <name> should be one of the following:
hbase.coprocessor.region.classes for RegionObservers and Endpoints.
hbase.coprocessor.wal.classes for WALObservers.
hbase.coprocessor.master.classes for MasterObservers.
<value> must contain the fully-qualified class name of your coprocessor’s implementation class.
For example to load a Coprocessor (implemented in class SumEndPoint.java) you have to create following entry in RegionServer’s ‘hbase-site.xml’ file (generally located under ‘conf’ directory):
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.myname.hbase.coprocessor.endpoint.SumEndPoint</value>
</property>
If multiple classes are specified for loading, the class names must be comma-separated. The framework attempts to load all the configured classes using the default class loader. Therefore, the jar file must reside on the server-side HBase classpath.
Coprocessors which are loaded in this way will be active on all regions of all tables. These are also called system Coprocessor. The first listed Coprocessors will be assigned the priority Coprocessor.Priority.SYSTEM. Each subsequent coprocessor in the list will have its priority value incremented by one (which reduces its priority, because priorities have the natural sort order of Integers).
When calling out to registered observers, the framework executes their callbacks methods in the sorted order of their priority. Ties are broken arbitrarily. Put your code on HBase’s classpath. One easy way to do this is to drop the jar (containing you code and all the dependencies) into the lib/ directory in the HBase installation. Restart HBase.
Static Unloading
- Delete the coprocessor’s <property> element, including sub-elements, from hbase-site.xml.
- Restart HBase.
- Optionally, remove the coprocessor’s JAR file from the classpath or HBase’s lib/ directory.
Dynamic Loading
You can also load a coprocessor dynamically, without restarting HBase. This may seem preferable to static loading, but dynamically loaded coprocessors are loaded on a per-table basis, and are only available to the table for which they were loaded. For this reason, dynamically loaded tables are sometimes called Table Coprocessor.
In addition, dynamically loading a coprocessor acts as a schema change on the table, and the table must be taken offline to load the coprocessor.
There are three ways to dynamically load Coprocessor.
Using HBase Shell
Disable the table using HBase Shell:
hbase> disable ‘users’
Load the Coprocessor, using a command like the following:
hbase alter ‘users’, METHOD => ‘table_att’, ‘Coprocessor’=>’hdfs://<namenode>:<port>/
user/<hadoop-user>/coprocessor.jar| org.myname.hbase.Coprocessor.RegionObserverExample|1073741823|
arg1=1,arg2=2′
The Coprocessor framework will try to read the class information from the coprocessor table attribute value. The value contains four pieces of information which are separated by the pipe (|) character.
- File path: The jar file containing the Coprocessor implementation must be in a location where all region servers can read it.
- You could copy the file onto the local disk on each region server, but it is recommended to store it in HDFS.
- HBASE-14548 allows a directory containing the jars or some wildcards to be specified, such as: hdfs://<namenode>:<port>/user/<hadoop-user>/ or hdfs://<namenode>:<port>/user/<hadoop-user>/*.jar. Please note that if a directory is specified, all jar files(.jar) in the directory are added. It does not search for files in sub-directories. Do not use a wildcard if you would like to specify a directory. This enhancement applies to the usage via the JAVA API as well.
- Class name: The full class name of the Coprocessor.
- Priority: An integer. The framework will determine the execution sequence of all configured observers registered at the same hook using priorities. This field can be left blank. In that case the framework will assign a default priority value.
- Arguments (Optional): This field is passed to the Coprocessor implementation. This is optional.
Enable the table. hbase(main):003:0> enable ‘users’
Verify that the coprocessor loaded: hbase(main):04:0> describe ‘users’
The coprocessor should be listed in the TABLE_ATTRIBUTES.
Examples
HBase ships examples for Observer Coprocessor. A more detailed example is given below. These examples assume a table called users, which has two column families personalDet and salaryDet, containing personal and salary details. Below is the graphical representation of the users table.
| Users Table | ||||||
| personalDet | salaryDet | |||||
| jverne | Jules | Verne | 02/08/1828 | 12000 | 9000 | 3000 |
| rowkey | name | lastname | dob | gross | net | allowances |
| admin | Admin | Admin | ||||
| cdickens | Charles | Dickens | 02/07/1812 | 10000 | 8000 | 2000 |
Apply for HBase Certification
https://www.vskills.in/certification/certified-hbase-professional
