IP Spoofing
IP address spoofing or IP spoofing is the creation of Internet Protocol (IP) packets with a forged source IP address, with the purpose of concealing the identity of the sender or impersonating another computing system.
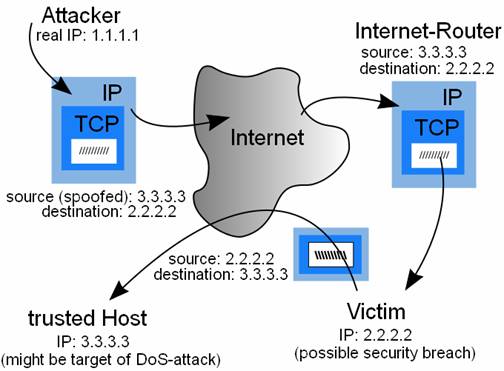
The basic protocol for sending data over the Internet network and many other computer networks is the Internet Protocol (“IP”). The header of each IP packet contains, among other things, the numerical source and destination address of the packet. The source address is normally the address that the packet was sent from. By forging the header so it contains a different address, an attacker can make it appear that the packet was sent by a different machine. The machine that receives spoofed packets will send a response back to the forged source address, which means that this technique is mainly used when the attacker does not care about the response or the attacker has some way of guessing the response.
Applications
IP spoofing is most frequently used in denial-of-service attacks. In such attacks, the goal is to flood the victim with overwhelming amounts of traffic, and the attacker does not care about receiving responses to the attack packets. Packets with spoofed addresses are thus suitable for such attacks. They have additional advantages for this purpose—they are more difficult to filter since each spoofed packet appears to come from a different address, and they hide the true source of the attack. Denial of service attacks that use spoofing typically randomly choose addresses from the entire IP address space, though more sophisticated spoofing mechanisms might avoid unroutable addresses or unused portions of the IP address space. The proliferation of large botnets makes spoofing less important in denial of service attacks, but attackers typically have spoofing available as a tool, if they want to use it, so defenses against denial-of-service attacks that rely on the validity of the source IP address in attack packets might have trouble with spoofed packets. Backscatter, a technique used to observe denial-of-service attack activity in the Internet, relies on attackers’ use of IP spoofing for its effectiveness.
IP spoofing can also be a method of attack used by network intruders to defeat network security measures, such as authentication based on IP addresses. This method of attack on a remote system can be extremely difficult, as it involves modifying thousands of packets at a time. This type of attack is most effective where trust relationships exist between machines. For example, it is common on some corporate networks to have internal systems trust each other, so that users can log in without a username or password provided they are connecting from another machine on the internal network (and so must already be logged in). By spoofing a connection from a trusted machine, an attacker may be able to access the target machine without authentication.
When IP spoofing is used to hijack a browser, a visitor who types in the URL (Uniform Resource Locator) of a legitimate site is taken to a fraudulent Web page created by the hijacker. For example, if the hijacker spoofed the Library of Congress Web site, then any Internet user who typed in the URL www.loc.gov would see spoofed content created by the hijacker.
If a user interacts with dynamic content on a spoofed page, the highjacker can gain access to sensitive information or computer or network resources. He could steal or alter sensitive data, such as a credit card number or password, or install malware . The hijacker would also be able to take control of a compromised computer to use it as part of a zombie army in order to send out spam.
Web site administrators can minimize the danger that their IP addresses will be spoofed by implementing hierarchical or one-time passwords and data encryption/decryption techniques. Users and administrators can protect themselves and their networks by installing and implementing firewalls that block outgoing packets with source addresses that differ from the IP address of the user’s computer or internal network.
Legitimate Use
Spoofed IP packets are not incontrovertible evidence of malicious intent: in performance testing of websites, hundreds or even thousands of “vusers” (virtual users) may be created, each executing a test script against the website under test, in order to simulate what will happen when the system goes “live” and a large number of users log on at once.
Since each user will normally have its own IP address, commercial testing products (such as HP LoadRunner and WebLOAD) can use IP spoofing, allowing each user its own “return address” as well.
Vulnerable Services
Configuration and services that are vulnerable to IP spoofing:
- RPC (Remote procedure call services)
- Any service that uses IP address authentication
- The X Window System
- The R services suite (rlogin, rsh, etc.)
Countermeasure
Packet filtering is one defense against IP spoofing attacks. The gateway to a network usually performs ingress filtering, which is blocking of packets from outside the network with a source address inside the network. This prevents an outside attacker spoofing the address of an internal machine. Ideally the gateway would also perform egress filtering on outgoing packets, which is blocking of packets from inside the network with a source address that is not inside. This prevents an attacker within the network performing filtering from launching IP spoofing attacks against external machines.
It is also recommended to design network protocols and services so that they do not rely on the IP source address for authentication.
Some upper layer protocols provide their own defense against IP spoofing attacks. For example, Transmission Control Protocol (TCP) uses sequence numbers negotiated with the remote machine to ensure that arriving packets are part of an established connection. Since the attacker normally can’t see any reply packets, the sequence number must be guessed in order to hijack the connection. The poor implementation in many older operating systems and network devices, however, means that TCP sequence numbers can be predicted.
HTTP Tunneling
HTTP tunneling is a technique by which communications performed using various network protocols are encapsulated using the HTTP protocol, the network protocols in question usually belonging to the TCP/IP family of protocols. The HTTP protocol therefore acts as a wrapper for a channel that the network protocol being tunneled uses to communicate.
The HTTP stream with its covert channel is termed an HTTP tunnel.
HTTP tunnel software consists of client-server HTTP tunneling applications that integrate with existing application software, permitting them to be used in conditions of restricted network connectivity including firewalled networks, networks behind proxy servers, and network address translation.
An HTTP tunnel is used most often as a means for communication from network locations with restricted connectivity – most often behind NATs, firewalls, or proxy servers, and most often with applications that lack native support for communication in such conditions of restricted connectivity. Restricted connectivity in the form of blocked TCP/IP ports, blocking traffic initiated from outside the network, or blocking of all network protocols except a few is a commonly used method to lock down a network to secure it against internal and external threats.
Mechanism
The mediater server unwraps the actual data before forwarding it to the remote host in question. Symmetrically, when it receives data from the remote host, it wraps it in the HTTP protocol before sending it as part of an HTTP response to the application.
In this situation, the application plays the role of a tunneling client, while the remote host plays the role of the server being communicated with.
HTTP CONNECT tunneling
A variation of HTTP tunneling when behind an HTTP Proxy Server is to use the “CONNECT” HTTP method.
In this mechanism, the client asks an HTTP Proxy server to forward the TCP connection to the desired destination. The server then proceeds to make the connection on behalf of the client. Once the connection has been established by the server, the Proxy server continues to proxy the TCP stream to and from the client. Note that only the initial connection request is HTTP – after that, the server simply proxies the established TCP connection.
This mechanism is how a client behind an HTTP proxy can access websites using SSL (i.e. HTTPS).
Not all HTTP Proxy Servers support this feature, and even those that do, may limit the behaviour (for example only allowing connections to the default HTTPS port 443, or blocking traffic which doesn’t appear to be SSL).
HTTP tunneling without using CONNECT
In some networks, the use of CONNECT method is restricted to some trusted sites. In such cases, an HTTP tunnel can still be implemented using only the usual HTTP methods as POST, GET, PUT and DELETE. This is similar to the approach used in Bidirectional-streams Over Synchronous HTTP (BOSH).
In this proof-of-concept program , the server runs outside the protected network and acts as a special HTTP server. The client program is run on a computer inside the protected network. Whenever any network traffic is passed to the client, it repackages it as an HTTP request and relays it to the outside server, which extracts and executes the original network request for the client. The response to the request, sent to the server, is then repackaged as an HTTP response and relayed back to the client. Since all traffic is encapsulated inside normal GET and POST requests and responses, this approach works through most proxies and firewalls.
HTTP tunnel clients
There are several free or open-source, and commercial HTTP tunneling client applications that allow even applications that lack native tunneling support to communicate from locations with restricted connectivity.
The free or open-source HTTP tunneling clients are usually packaged as a pair of applications, one of which performs the role of the mediator server, the other performing the role of the tunneling client. This requires the user to have access to their own server that they can run the mediator server software on.
The commercial HTTP tunneling client applications are provided by companies that run their own mediator server farms. They charge for the service provided, with various tiers of service that depend on the bandwidth provided.
Uses
- To use applications (games/IM clients/browsers) from behind restrictive firewalls or proxy servers
- To access blocked sites/content (e.g., BBC iPlayer if you are outside of the UK)
- Watch blocked videos (by country) on YouTube
- To share some confidential resource over HTTP securely
